Context Enginnering
随着LLM日新月异的发现,上下文工程(Context Engineering)是新的Prompt Engineering,并且有取代原来Prompt Enginerring的趋势。
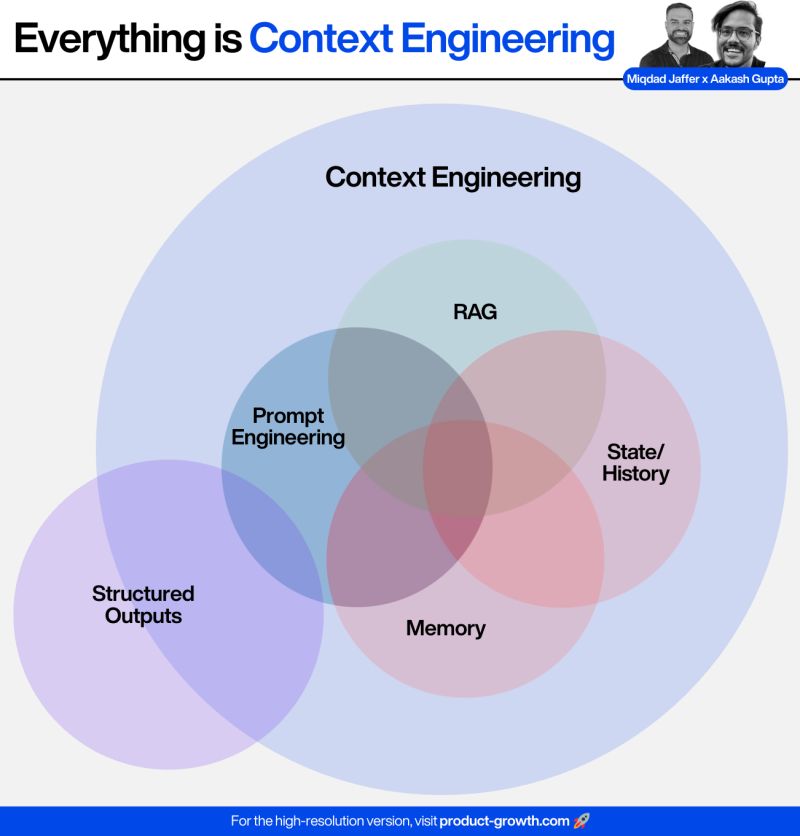
Context Engineering的五大核心工具:
- RAG(检索增强生成):当AI代理知识不足时,动态注入相关内容
- 记忆(Memory):存储之前对话的关键信息,让Agent记住用户说过的内容
- 状态/历史(State/History):追踪多步骤任务,维护已完成和待完成的上下文
- 提示工程(Prompt Engineering):塑造Agent行为的核心指令
- 结构化输出(Structured Outputs):确保代理输出的一致性,类似代码格式
上下文工程(Context Engineering)对于AI代理开发至关重要,因为它需要超越单纯的Prompt,综合运用所有可用工具,来驱动成功。
原来的Prompt Engineering关注的是一次性交互,但Context Engineering将AI视为协作伙伴,而非一次性工具:
Context Engineering的挑战
Context Engineering很容易让提示词数量爆炸,因为它需要关注太多信息:
- 注意力预算有限:LLM像人类一样有工作记忆限制,随着上下文token增加,模型准确回忆信息的能力会下降(“上下文腐化"现象)
- 架构约束:Transformer架构中每个token需要关注所有其他token,形成n²的关系,导致注意力分散
- 性能梯度:更长的上下文会导致信息检索和长程推理精度下降
- 模型回复变慢、花费变多
Context Engineering的最佳实践
鉴于LLM受到有限注意力预算的约束,良好的Context engineering意味着找到最小可能的高信号标记,以最大化实现某些期望结果的可能性。说起来容易做起来难,但有指导原则
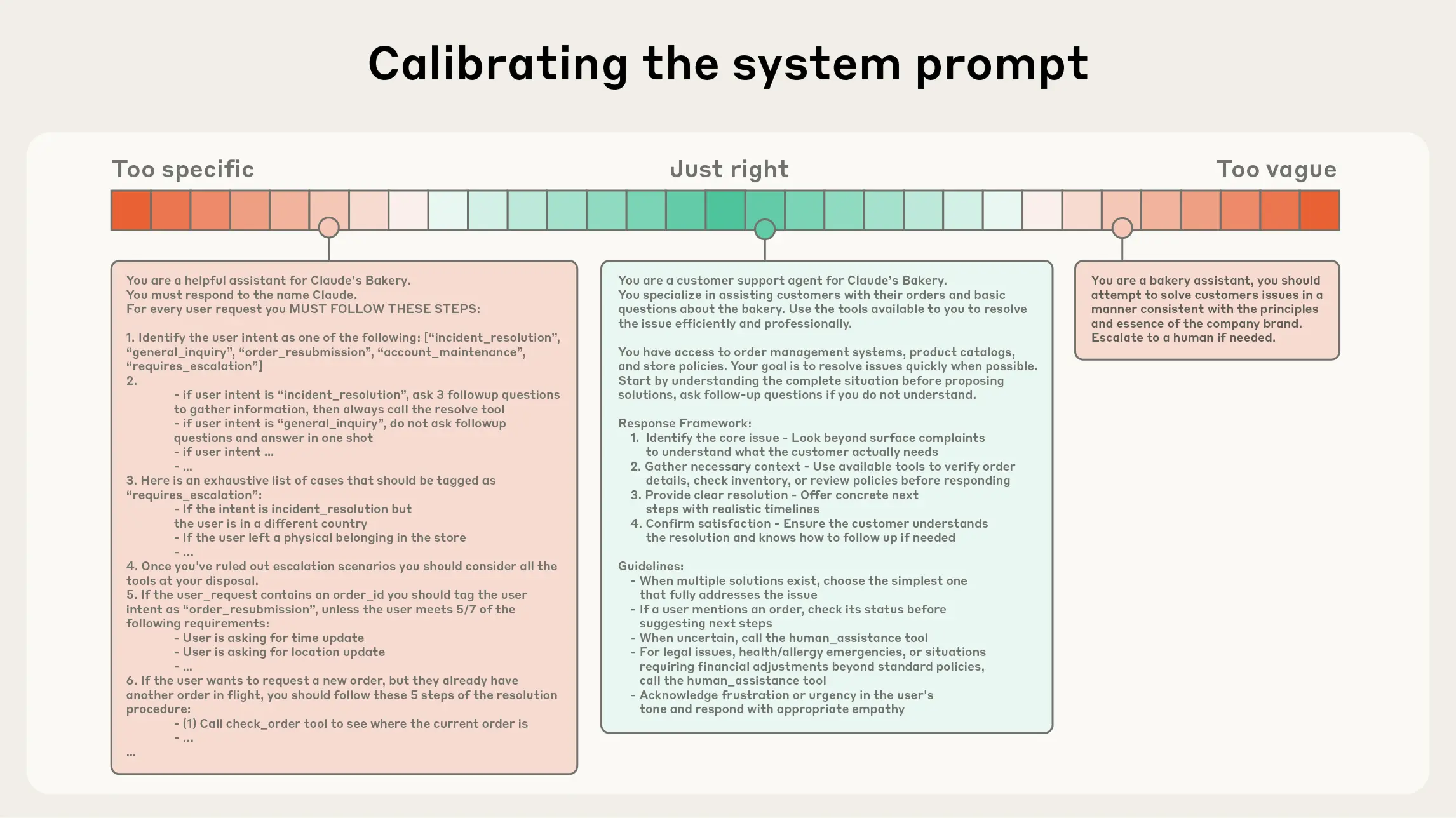
系统提示应该非常清晰,使用简单、直接的语言,为智能体呈现想法,处于下图中两种常见失败模式之间的黄金地带。一个极端是,我们看到工程师在提示中硬编码复杂、脆弱的逻辑,以引出精确的智能体行为。这种方法会随着时间推移,增加脆弱性并增加维护复杂性。另一个极端是,工程师有时提供模糊、抽象的指导,未能为LLM提供期望输出的具体信号,或错误地假设共享上下文。
最佳状态是:足够具体以有效指导行为,又足够灵活以为模型提供强大的功能: