Text Summarization II - 使用 Langchain 进行文本摘要
在这里,我们将使用 Langchain 对 PDF 文件运行对 Bedrock 的小块顺序调用。模型将从全文中返回最终摘要。
在处理大型文档时,我们可能会面临一些挑战:
- 大型文档可能不适合模型的上下文长度
- 模型可能会对大文档产生幻觉
- 我们可能会遇到内存不足等错误
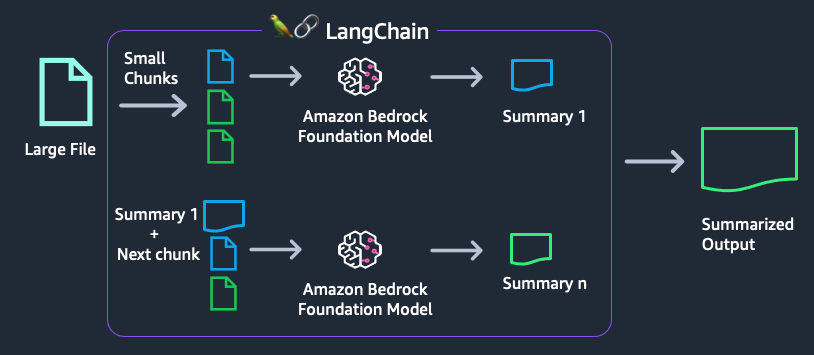
为了解决这些问题,我们将文件分成小块,分批调用模型,单独传递每个块以获得摘要。汇总所有块后,将使用所有汇总再次调用模型以获取这些汇总的汇总。此方法使用 Langchain 的 map_reduce 选项。 Langchain 中还有其他方法来汇总和处理大文件。参考: https://python.langchain.com/docs/use_cases/summarization
此示例将基于 Amazon致股东的信: https://www.aboutamazon.com/news/company-news/amazon-ceo-andy-jassy-2022-letter-to-shareholders
下载这封信:
wget https://pingfan.s3.amazonaws.com/files/2022-letter.txt
我们将:
- 加载大文档。
- LangChain将其分割成多个块(chunking)。
- 第一个块被发送到模型。模型返回相应的摘要。
- LangChain 获取下一个块并将其附加到返回的摘要中,然后向模型发出新的请求。它按顺序继续,直到处理完所有块。
- 最后,根据整个内容得到一个最终的总结。
先安装依赖:
pip3 install \
"langchain>=0.1.11" \
sqlalchemy -U \
"faiss-cpu>=1.7,<2" \
"pypdf>=3.8,<4" \
pinecone-client==2.2.4 \
apache-beam==2.52. \
tiktoken==0.5.2 \
"ipywidgets>=7,<8" \
matplotlib==3.8.2 \
anthropic==0.9.0
pip3 install transformers
代码如下:
import json
import os
import sys
import boto3
from langchain.llms.bedrock import Bedrock
def print_ww(*args, width: int = 100, **kwargs):
"""Like print(), but wraps output to `width` characters (default 100)"""
buffer = StringIO()
try:
_stdout = sys.stdout
sys.stdout = buffer
print(*args, **kwargs)
output = buffer.getvalue()
finally:
sys.stdout = _stdout
for line in output.splitlines():
print("\n".join(textwrap.wrap(line, width=width)))
boto3_bedrock = boto3.client('bedrock-runtime')
# LangChain Bedrock类需要指定LLM,并且可以传递参数进行推理。您在此处指定 Amazon Titan Text Large`model_id`并将 Titan 的推理参数传递给`textGenerationConfig`。
modelId = "amazon.titan-tg1-large"
llm = Bedrock(
model_id=modelId,
model_kwargs={
"maxTokenCount": 4096,
"stopSequences": [],
"temperature": 0,
"topP": 1,
},
client=boto3_bedrock,
)
shareholder_letter = "2022-letter.txt"
with open(shareholder_letter, "r") as file:
letter = file.read()
# 将看到警告,指示文本文件中的token数量超过了该模型的最大token数量。
llm.get_num_tokens(letter)
运行上面代码,会提示:

将长文本分割成块
文本太长,无法适应提示,因此我们将其分成较小的块。LangChain支持RecursiveCharacterTextSplitter,递归地将长文本分割成块,直到每个块的大小变得小于chunk_size。文本由separators=["\n\n", "\n"]分成块,这避免了将每个段落分成多个块。
每个块使用 4,000 个字符,我们可以分别获得每个部分的摘要。块中的标记或单词片段的数量取决于文本。
在上面代码后面追加以下代码:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n"], chunk_size=4000, chunk_overlap=100
)
docs = text_splitter.create_documents([letter])
num_docs = len(docs)
num_tokens_first_doc = llm.get_num_tokens(docs[0].page_content)
print(
f"Now we have {num_docs} documents and the first one has {num_tokens_first_doc} tokens"
)
# Set verbose=True if you want to see the prompts being used
from langchain.chains.summarize import load_summarize_chain
summary_chain = load_summarize_chain(llm=llm, chain_type="map_reduce", verbose=False)
output = ""
try:
output = summary_chain.run(docs)
except ValueError as error:
if "AccessDeniedException" in str(error):
print(f"\x1b[41m{error}\
\nTo troubeshoot this issue please refer to the following resources.\
\nhttps://docs.aws.amazon.com/IAM/latest/UserGuide/troubleshoot_access-denied.html\
\nhttps://docs.aws.amazon.com/bedrock/latest/userguide/security-iam.html\x1b[0m\n")
class StopExecution(ValueError):
def _render_traceback_(self):
pass
raise StopExecution
else:
raise error
print_ww(output.strip())
load_summarize_chain提供了三种汇聚方式:stuff,map_reduce, 和refine。
stuff将所有块放入一个prompt中。因此,这将达到token的最大限制。map_reduce总结每个块,组合摘要,最后合并起来一起总结。如果合并的摘要太大,则会引发错误。refine总结第一个块,然后用第一个总结加到第二个块。重复相同的过程,直到汇总完所有块。
map_reduce和refine多次调用LLM才能获得最终摘要。我们用的是map_reduce。
运行结果:

RecursiveCharacterTextSplitter分词的结果:
