Prompt Router
Intelligent Prompt Routing和prompt caching有助于降低生成式AI应用的成本和延迟:
Bedrock智能提示路由 – 在调用模型时,现在可以使用来自同一模型系列的基础模型(FMs)
组合来帮助优化质量和成本。例如,使用Anthropic的Claude
模型系列,Bedrock可以根据提示的复杂性智能地在Claude 3.5 Sonnet和Claude 3 Haiku之间路由请求。同样,Bedrock可以在Meta Llama
3.1 70B和8B之间路由请求。Prompt Routing预测哪个模型将为每个请求提供最佳性能,同时优化响应质量和成本。这对于客户服务助手等应用程序特别有用,其中简单查询可以由更小、更快、更具成本效益的模型处理,而复杂查询则路由到更强大的模型。智能提示路由可以在不影响准确性的情况下将成本降低高达30%。
Bedrock提示缓存 – 现在可以在多个模型调用中缓存Prompt中经常使用的上下文。这对于重复使用相同上下文的应用程序特别有价值,例如文档问答系统(用户对同一文档提出多个问题)或需要维护代码文件上下文的编码助手。缓存的上下文在每次访问后最多可保留5分钟。Amazon Bedrock中的提示缓存可以将支持模型的成本降低高达90%,延迟降低高达85%。
这些功能使降低延迟和平衡性能与成本效率变得更加容易。让我们看看如何在应用中使用它们。
在控制台中使用Bedrock Prompt Routers
Prompt Routers使用先进的提示匹配和模型理解技术来预测每个模型对每个请求的性能,优化响应质量和成本。
进入控制台页面:

选择Anthropic prompt router:


从Prompt Router的配置中,看到它使用跨区域推理在Claude 3.5 Sonnet和Claude 3 Haiku之间路由请求。
选择Open in Playground, 使用Prompt Router进行聊天,并输入以下:
帮我生成一个quick sort python代码
结果很快就提供了。选择右侧的新Router metrics图标,查看Prompt Router选择了哪个模型。在这种情况下,由于问题相当简单,使用了Claude 3 Haiku。

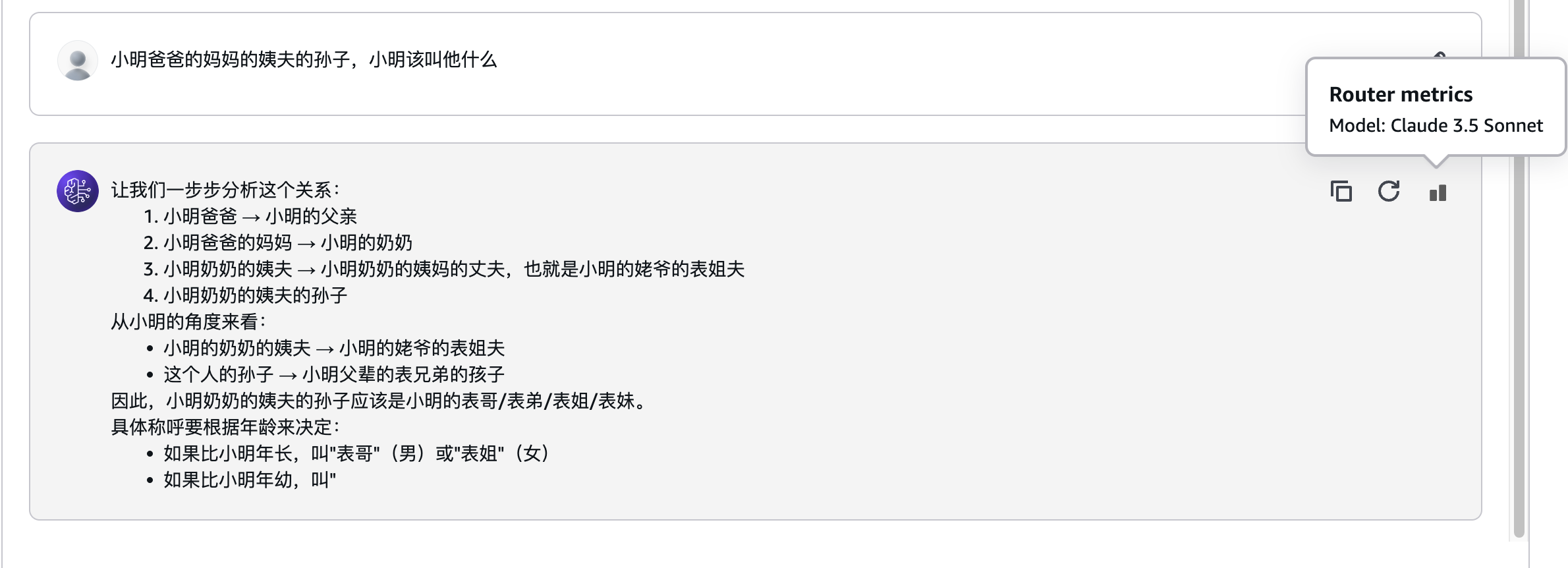
向同一Prompt Router提出一个复杂的问题:
小明爸爸的妈妈的姨夫的孙子,小明该叫他什么
这次,Prompt Router选择了Claude 3.5 Sonnet:
对于Meta Prompt Router,它使用Llama 3.1 70B和8B的跨区域推理,以70B模型作为后备:

CLI使用Prompt Router
使用ListPromptRouters列出AWS区域中现有的提示路由:
aws bedrock list-prompt-routers
输出:
{
"promptRouterSummaries": [
{
"promptRouterName": "Anthropic Prompt Router",
"routingCriteria": {
"responseQualityDifference": 0.0
},
"description": "Routes requests among models in the Claude family",
"createdAt": "2024-11-20T00:00:00+00:00",
"updatedAt": "2024-11-20T00:00:00+00:00",
"promptRouterArn": "arn:aws:bedrock:us-west-2:145197526627:default-prompt-router/anthropic.claude:1",
"models": [
{
"modelArn": "arn:aws:bedrock:us-west-2:145197526627:inference-profile/us.anthropic.claude-3-haiku-20240307-v1:0"
},
{
"modelArn": "arn:aws:bedrock:us-west-2:145197526627:inference-profile/us.anthropic.claude-3-5-sonnet-20240620-v1:0"
}
],
"fallbackModel": {
"modelArn": "arn:aws:bedrock:us-west-2:145197526627:inference-profile/us.anthropic.claude-3-5-sonnet-20240620-v1:0"
},
"status": "AVAILABLE",
"type": "default"
},
{
"promptRouterName": "Meta Prompt Router",
"routingCriteria": {
"responseQualityDifference": 0.0
},
"description": "Routes requests among models in the LLaMA family",
"createdAt": "2024-11-20T00:00:00+00:00",
"updatedAt": "2024-11-20T00:00:00+00:00",
"promptRouterArn": "arn:aws:bedrock:us-west-2:145197526627:default-prompt-router/meta.llama:1",
"models": [
{
"modelArn": "arn:aws:bedrock:us-west-2:145197526627:inference-profile/us.meta.llama3-1-8b-instruct-v1:0"
},
{
"modelArn": "arn:aws:bedrock:us-west-2:145197526627:inference-profile/us.meta.llama3-1-70b-instruct-v1:0"
}
],
"fallbackModel": {
"modelArn": "arn:aws:bedrock:us-west-2:145197526627:inference-profile/us.meta.llama3-1-70b-instruct-v1:0"
},
"status": "AVAILABLE",
"type": "default"
}
]
}
在进行API调用时, 将Prompt Router ARN设置为模型ID。例如:
aws bedrock-runtime converse \
--model-id arn:aws:bedrock:us-east-1:123412341234:default-prompt-router/anthropic.claude:1 \
--messages '[{ "role": "user", "content": [ { "text": "Alice has N brothers and she also has M sisters. How many sisters do Alices brothers have?" } ] }]'
在输出中,使用Prompt Router的调用包含一个新的trace部分,告诉我们实际使用了哪个模型。在这种情况下,是Anthropic的Claude 3.5 Sonnet:
{
"output": {
"message": {
"role": "assistant",
"content": [
{
"text": "To solve this problem, let's think it through step-by-step:\n\n1) First, we need to understand the relationships:\n - Alice has N brothers\n - Alice has M sisters\n\n2) Now, we need to consider who Alice's brothers' sisters are:\n - Alice herself is a sister to all her brothers\n - All of Alice's sisters are also sisters to Alice's brothers\n\n3) So, the total number of sisters that Alice's brothers have is:\n - The number of Alice's sisters (M)\n - Plus Alice herself (+1)\n\n4) Therefore, the answer can be expressed as: M + 1\n\nThus, Alice's brothers have M + 1 sisters."
}
]
}
},
. . .
"trace": {
"promptRouter": {
"invokedModelId": "arn:aws:bedrock:us-east-1:123412341234:inference-profile/us.anthropic.claude-3-5-sonnet-20240620-v1:0"
}
}
}

SDK使用Prompt Router
在调用模型时,将模型ID设置为ARN。例如:
import json
import boto3
bedrock_runtime = boto3.client(
"bedrock-runtime",
region_name="us-west-2",
)
MODEL_ID = "arn:aws:bedrock:us-west-2:145197526627:default-prompt-router/anthropic.claude:1" # 将这个进行替换,帐号id不同
user_message = "Describe the purpose of a 'hello world' program in one line."
messages = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
streaming_response = bedrock_runtime.converse_stream(
modelId=MODEL_ID,
messages=messages,
)
for chunk in streaming_response["stream"]:
if "contentBlockDelta" in chunk:
text = chunk["contentBlockDelta"]["delta"]["text"]
print(text, end="")
if "messageStop" in chunk:
print()
if "metadata" in chunk:
if "trace" in chunk["metadata"]:
print(json.dumps(chunk['metadata']['trace'], indent=2))
这个脚本打印响应文本和响应元数据中trace的内容。对于这个简单的请求,Prompt Router选择了更快、更经济的模型:
