Context命令
在 https://genai.kpingfan.com/01.basic-knowledge/03.context-enginnering/ ,我们讨论了Context Engineering:
它的一个缺点是,大模型的注意力预算有限:LLM像人类一样有工作记忆限制,随着上下文token增加,模型准确回忆信息的能力会下降(“上下文腐化"现象),带来消耗更多成本的同时,处理时间也变得更长。
在claude code中,有专门的/context命令,于可视化当前上下文窗口的使用情况,以彩色网格形式显示 token 分布。
当我们执行/context,它的输出如下:
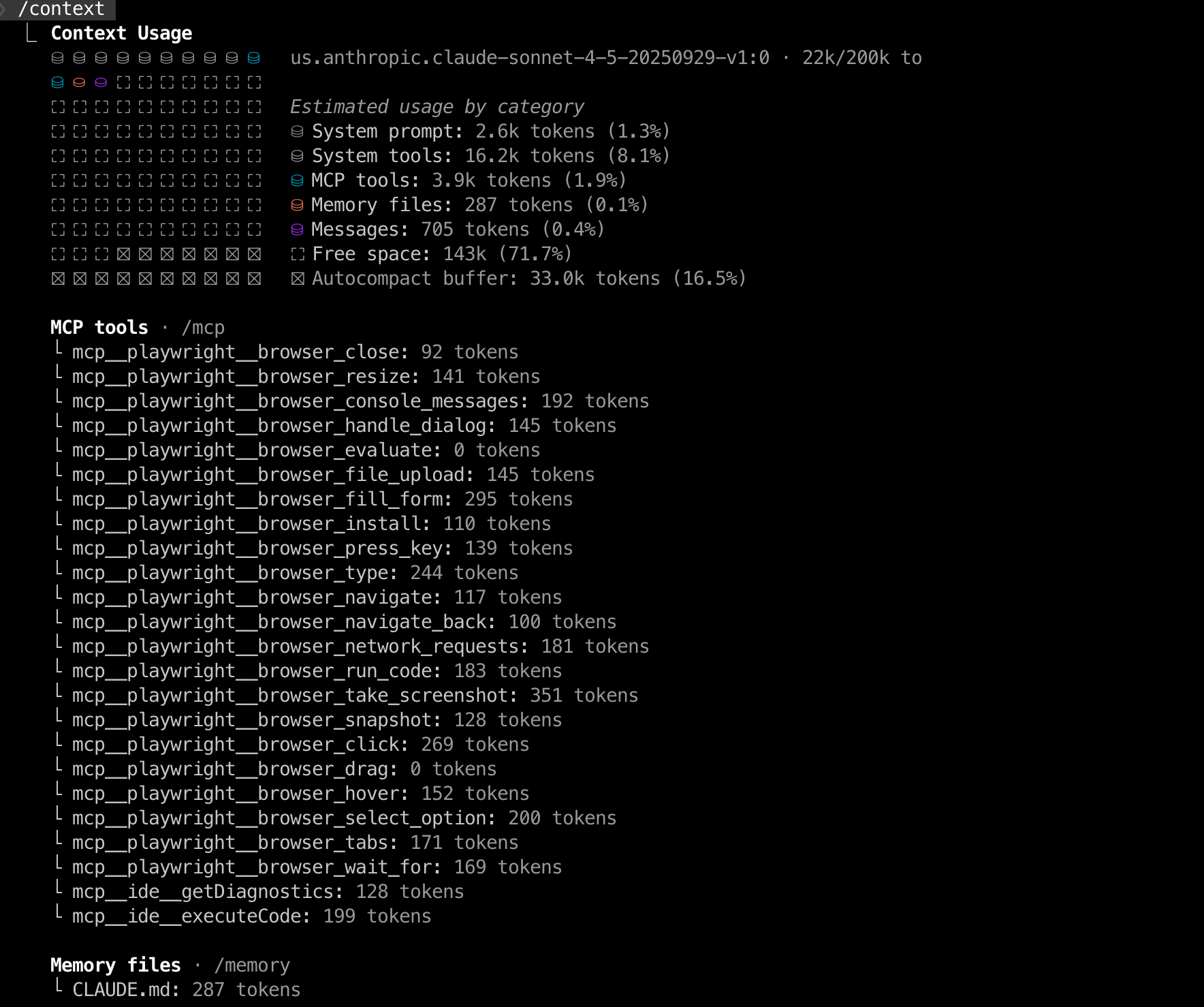
从这里面看到,claude模型的200K token限制,已经被MCP、系统工具、Memory(CLAUDE.md)等占用了22K。
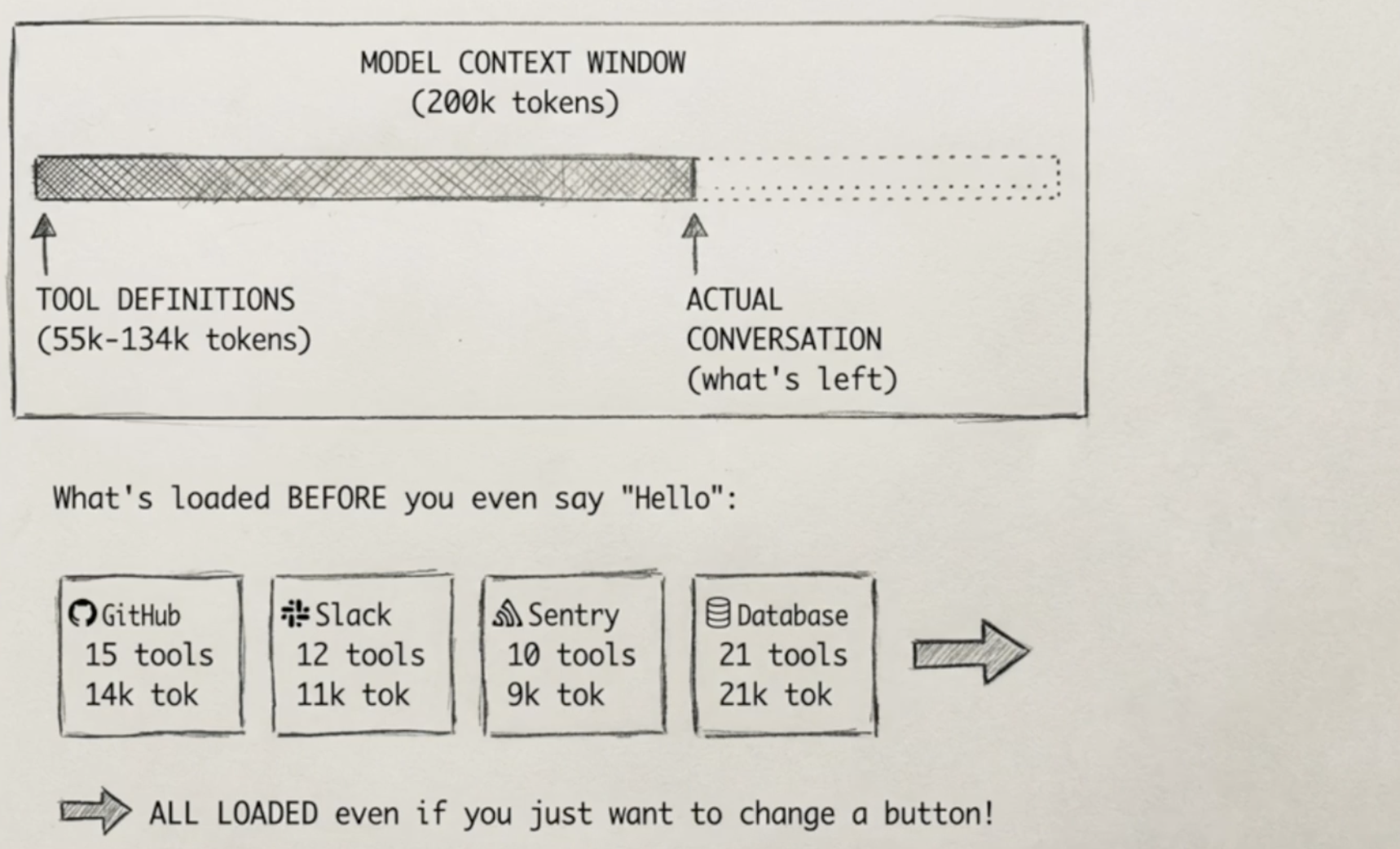
这意味着,即使我们发一句hello,也会传入大量的token给大模型。
这还是只安装了一个MCP tool的情况,如果我们安装了十几个或者更多MCP,我们会发这些Context加起来可能就占了200K token的大多数,留给用户的token就更少了。
使用 /context 可以让我们主动管理,比如释放或删除不必要的MCP,而非被动等待自动压缩。