小结
让我们再回到这张图:
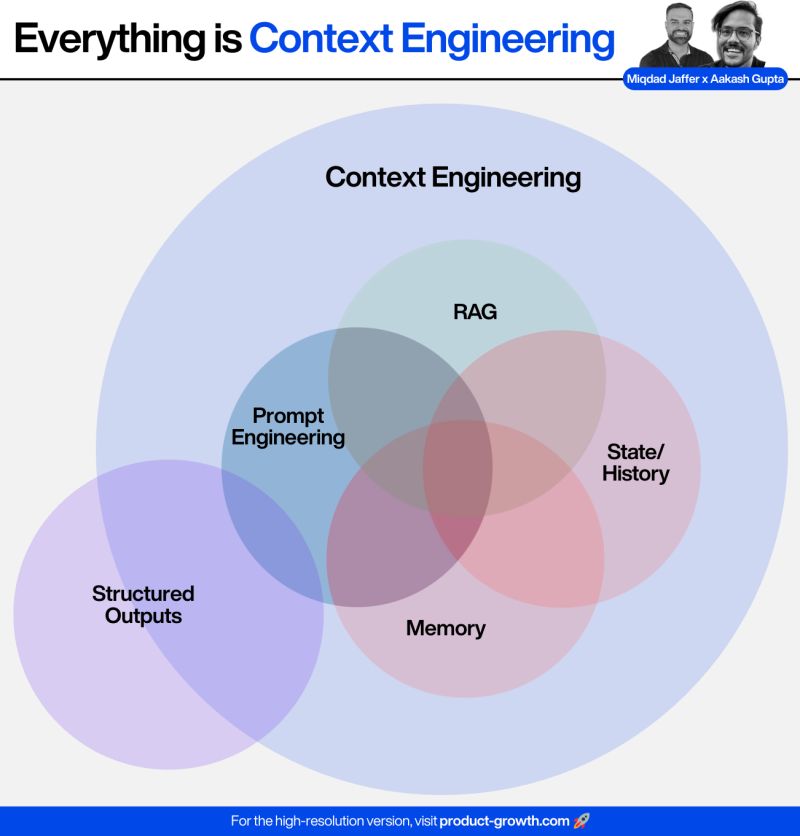
上面我们介绍了很多Claude Code的特性,本质上它还是Context Enginnering的完美落地。
我们也反复执行了这个/context命令:
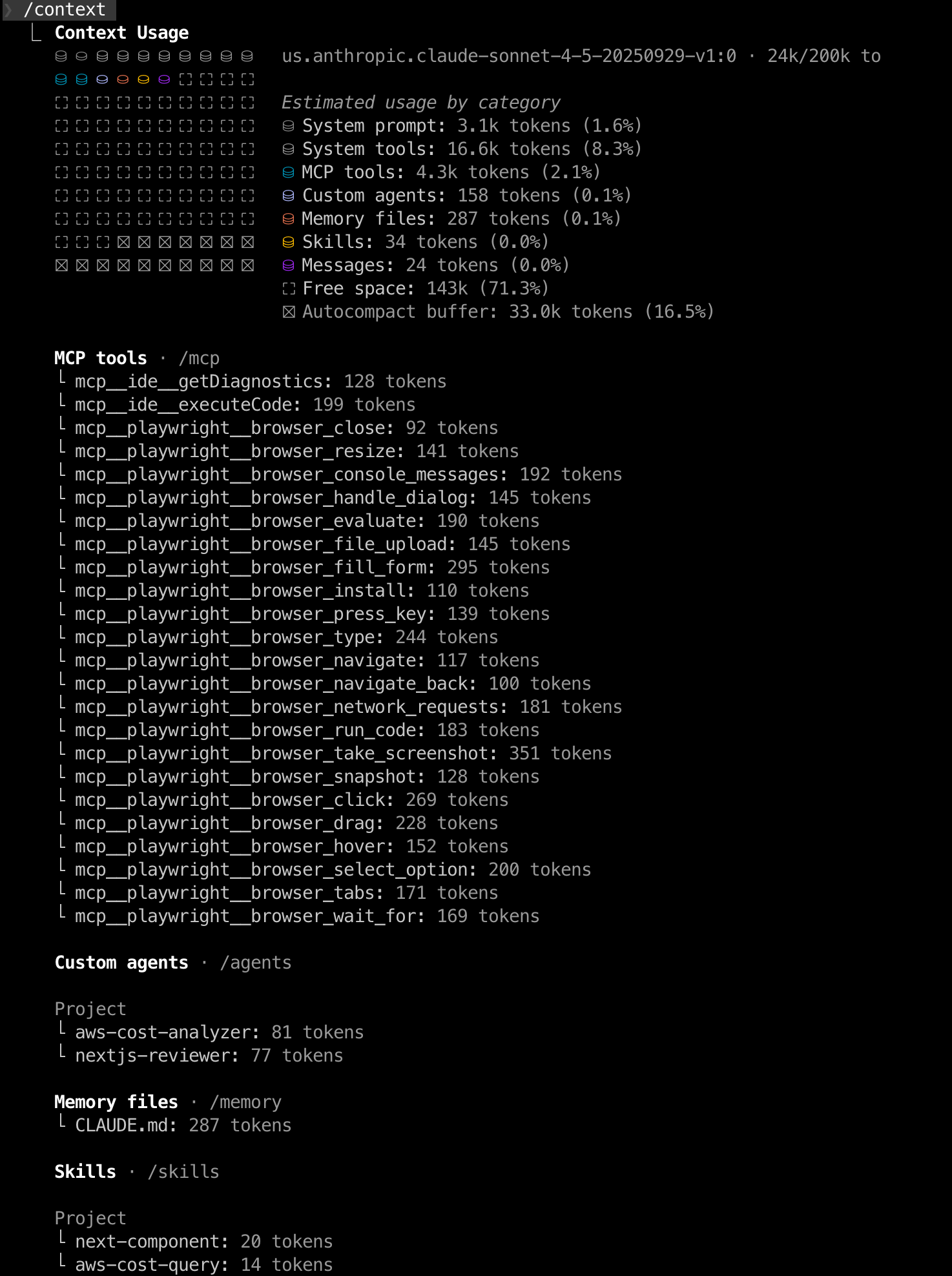
让我们再次总结下它。Claude Code 确实会将所有 MCP、skills、agent 的元数据加载到 context 中。从输出可以看到它们各自占用的 token 数:
Context 占用情况:
-
MCP tools(4.3k tokens)- 占用最多,因为需要包含每个工具的完整函数签名、参数定义和描述。你可以看到 24 个 Playwright 工具详细列表。
-
Custom agents(158 tokens)- 相对较少,只包含 agent 的
name和description字段,用于匹配触发条件。完整的 agent prompt 不会加载到主 context,只有在实际调用时才会加载到 agent 的独立 context 中。 -
Skills(34 tokens)- 占用最少,只包含 skill 名称和简短描述。完整的 skill 内容同样不会预加载,只在调用时展开。
-
System tools(16.6k tokens)- 这是内置工具如 Read、Write、Edit、Bash、Grep、Glob 等的定义,占用最多。
这种设计很巧妙:通过只加载元数据(名称 + 简短描述),Claude Code 可以让我知道有哪些工具可用,同时不会消耗太多 context。完整内容只在实际使用时才加载。
同名冲突的优先级
当有相同名称的 MCP/Skills/Agent 时,它们实际上不会冲突,因为它们使用不同的调用机制:
Skills - 通过 Skill tool 调用,语法:Skill(skill: "skill-name")。用户可以用 /skill-name 快捷方式调用。
Agents - 通过 Task tool 调用,语法:Task(subagent_type: "agent-name")。用户可以说 “使用 agent-name 做某事”。
MCP tools - 直接通过函数名调用,语法:mcp__server__tool_name()。函数名有 mcp__ 前缀和服务器名称,不太可能重名。
调用机制不同,它们不会产生歧义。
假如我们有以下两个skill和agent:
Skill: aws-cost-query(14 tokens)- 快速查询 AWS 成本数据的命令式操作。
Agent: aws-cost-analyzer(81 tokens)- 深度分析 AWS 成本的专用代理。
这两者功能相似但场景不同。当用户说 “查询 12 月成本” 时,Claude Code可能会优先使用 skill(快速简单)。当用户说 “分析并生成成本报告” 时,Claude Code可能会使用 agent(需要深度分析和独立 context)。
Token 优化建议
从上面来看,MCP占用还是比较多,目前 24 个 Playwright tools 就占了 4.3, 我们可以考虑只启用必要的 MCP 服务器,禁用不常用的 MCP 工具,或者精简 agent description 到最核心的触发关键词。