构建AI Agent
本章节我们将创建一个使用知识库内容来回答问题的对话机器人:
- 首先我们会用Dify的知识库功能创建知识库。
- 然后创建一个聊天助手应用,并体验开箱即用的聊天增强以及工具箱中的内容审核和标注回复等功能。
- 最后在聊天助手中导入知识库作为上下文验证效果。
知识库创建
在Dify控制台的知识库功能区点击创建知识库,DIfy目前支持三种方式的数据源(v0.6.11),本实验我们使用导入已有文本的方式。
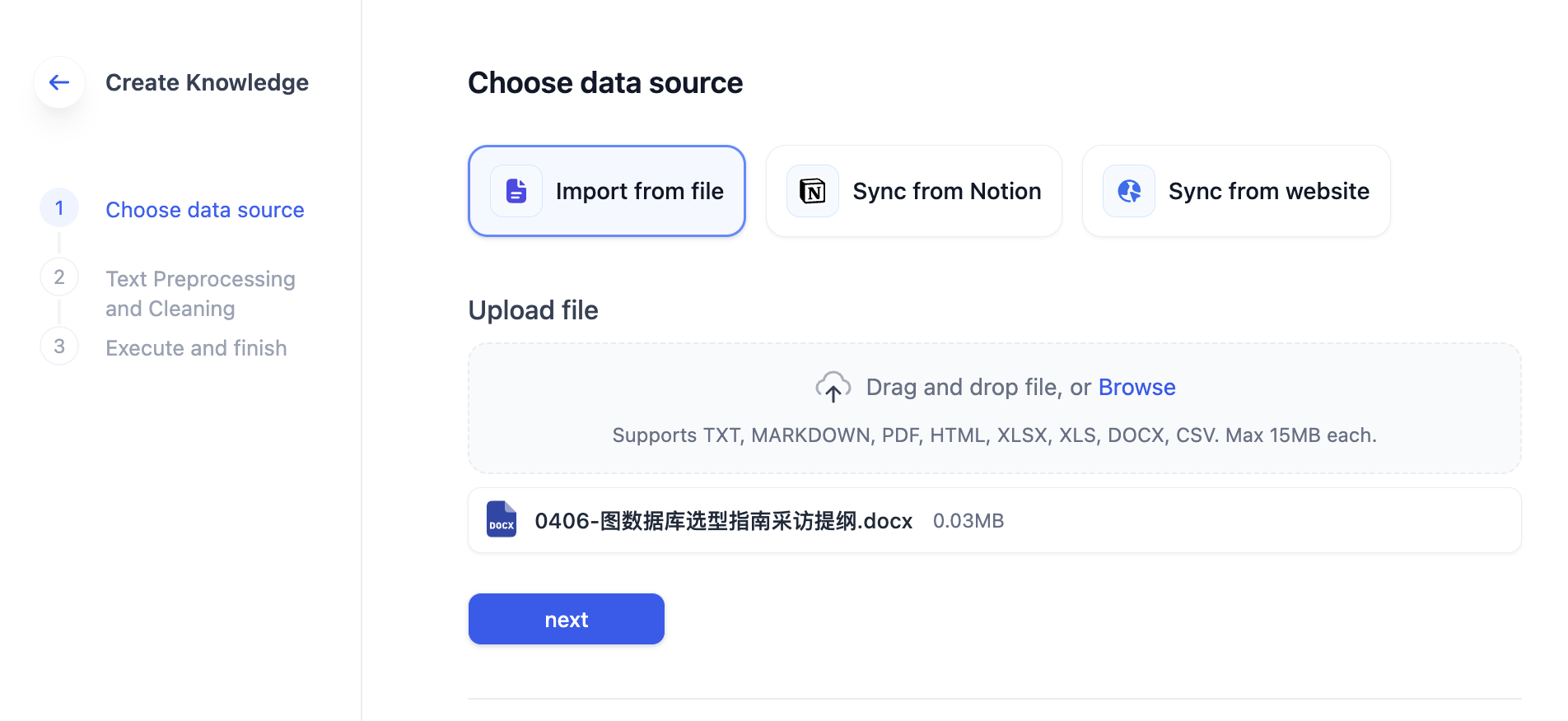
选择“导入已有文本”,上传刚刚下载的文档,然后点击下一步按钮导入
设置文本分段和清洗
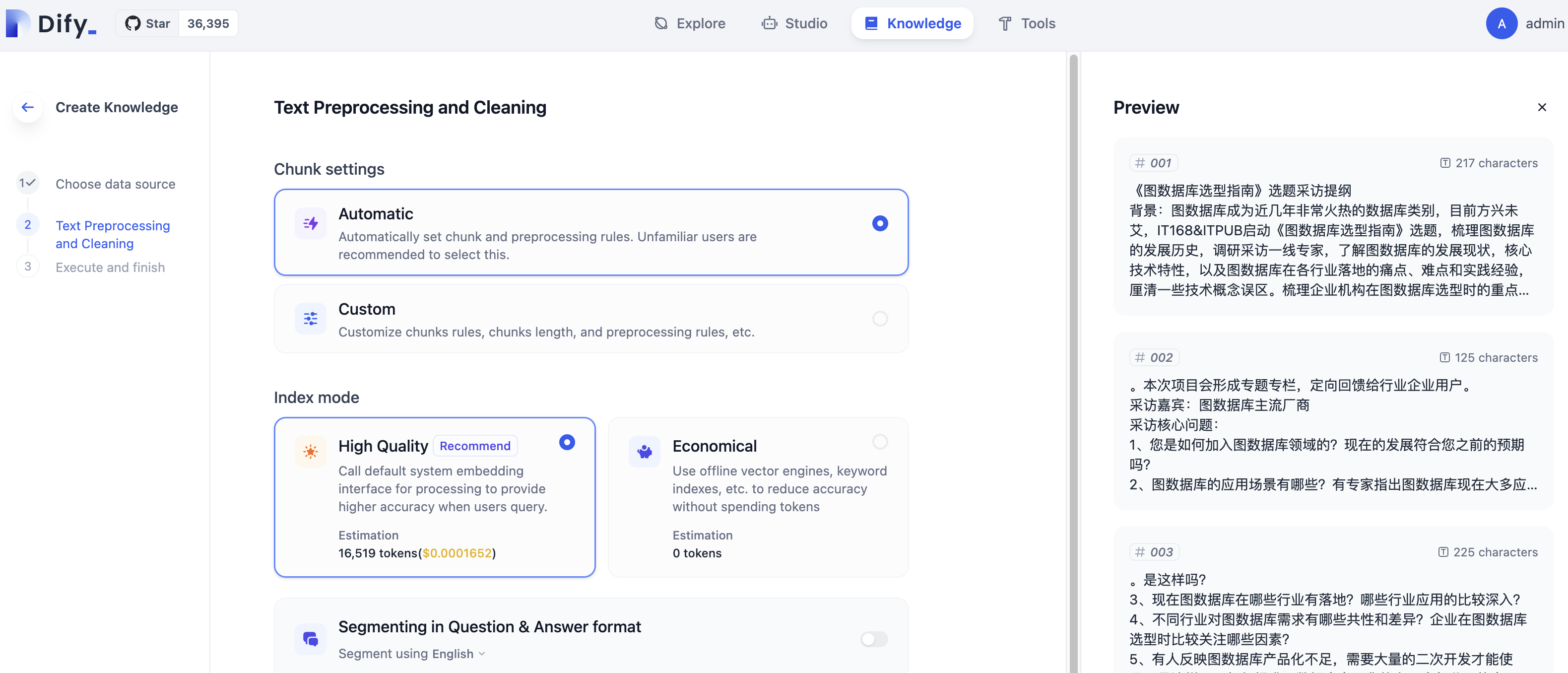
Dify以一种实时交互的方式展示切片信息,方便对chunk不熟悉的用户有一个直观的感受,并同时提供了丰富的分段逻辑和切片清洗逻辑。
我们先选择“自动分段与清洗”这种方式观察一下右边的分段预览,这里我们可以看到Dify智能化的将文本分段大小不等的段落。
切换到“自定义”分段,我们可以看到dify系统支持进行自定义的切片逻辑,在自定义分段设置中可以对文档内容中的特殊标识符,特殊字符等进行处理,也可以对分段的长度和重叠进行设置,此处请自行尝试调整分段参数
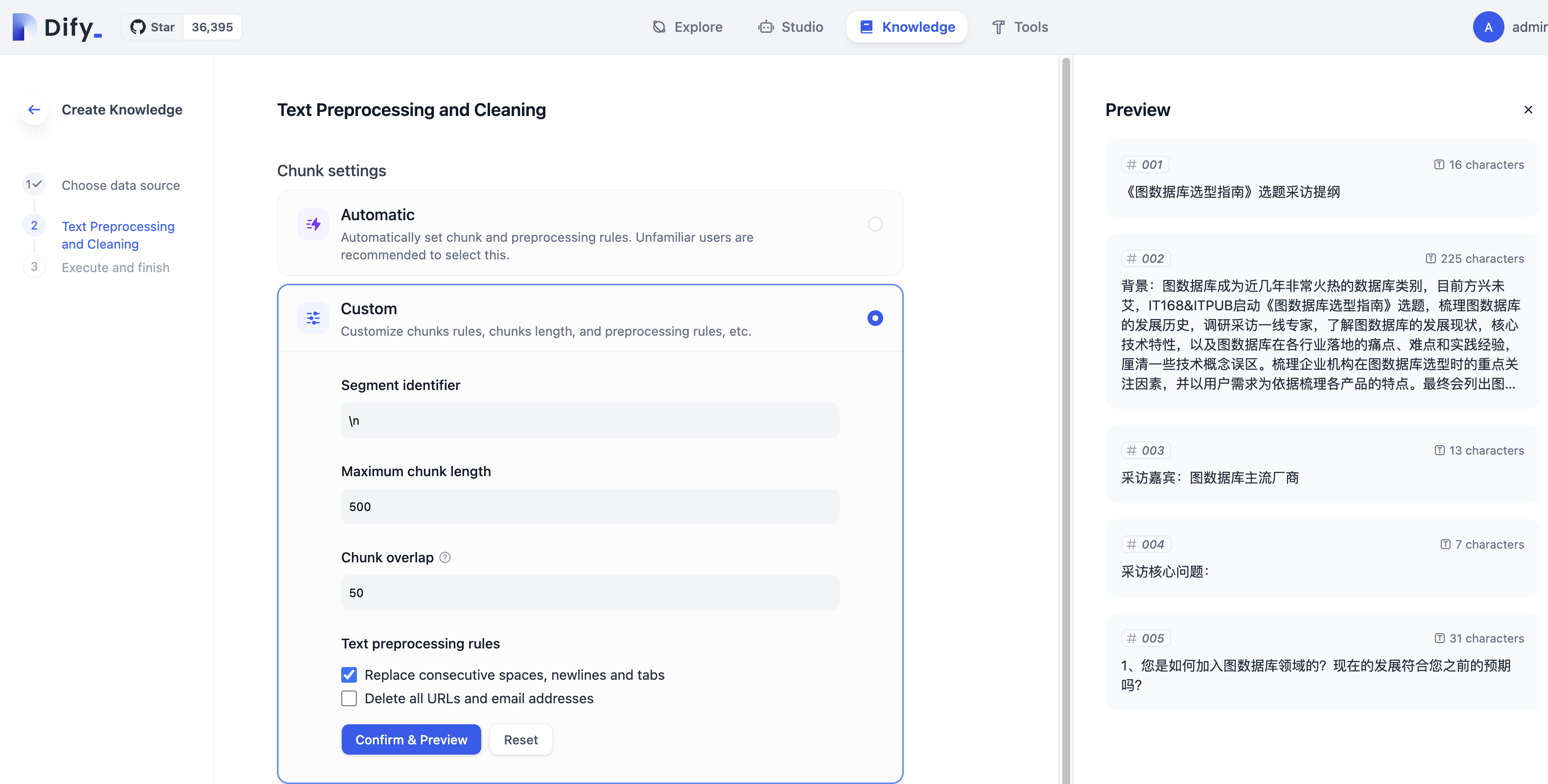
因为不同数据格式,比如图片、表格、分栏等,切片对搜索精准率的影响非常大,甚至中英文等切片规则也有较大差异。这些都需要在实际工程中进行验证测试,不能一概而论,而Dify为用户提供了非常大的灵活性。
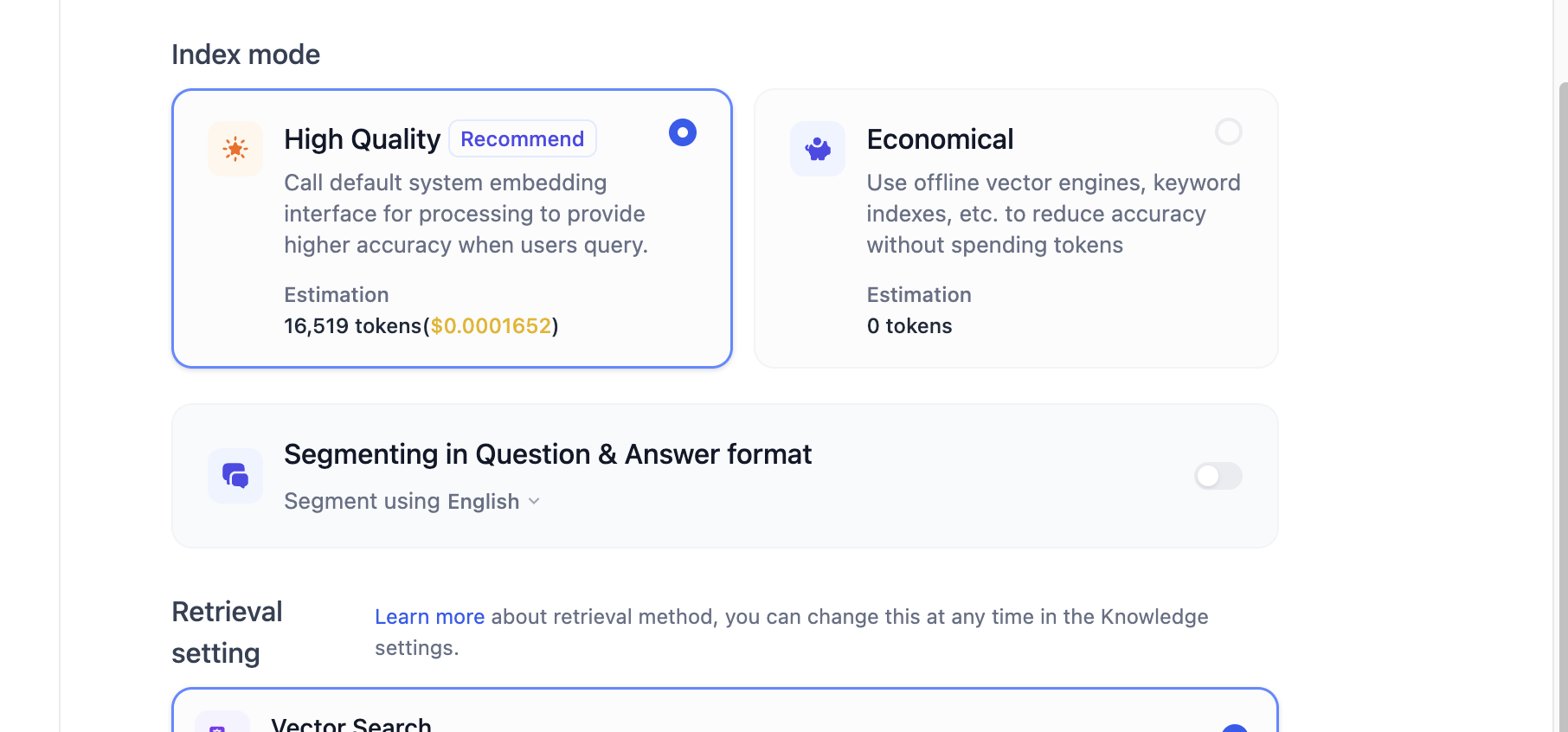
建立索引
Dify提供了三种索引方式:
- 第一种高质量模式,通过Embedding进行向量化,后续依赖向量数据库的近似匹配完成搜索,需要消耗一定的token;
- 第二种经济模式,通过传统关键词搜索的方式构建索引,采用类似ES的组件完成搜索,降低了准确度但无需花费 Token,这种方式倒排索引仅提供了Top_K结果的返回,有兴趣的同学可以自行测试。
- 第三种Q&A模式(仅社区版支持),在文档经过分段后,经过总结为每一个分段生成 Q&A 匹配对,当用户提问时,系统会找出与之最相似的问题,然后返回对应的分段作为答案。这种方式更加精确,因为它直接针对用户问题进行匹配,可以更准确地获取用户真正需要的信息。
实验中我们选择高质量索引方式
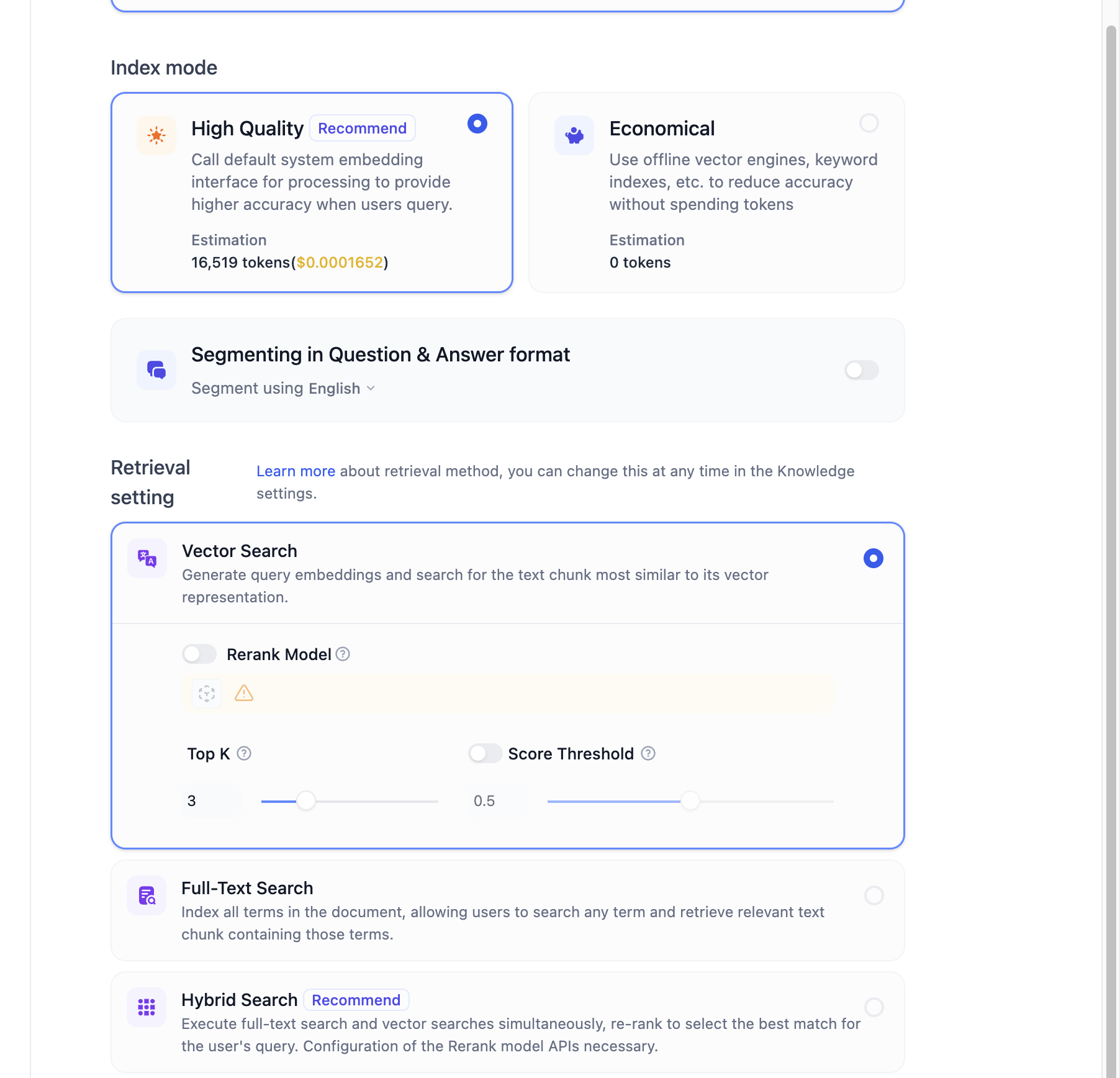
高质量索引支持3种类型的检索设置:
- 向量检索
- 全文检索
- 混合检索,混合检索=向量检索+全文检索。
Rerank模型可以大大提高RAG召回的准确率。如果在“模型供应商”页面配置了支持 Rerank 的模型后,在检索设置中打开“Rerank 模型”,系统会在语义检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
这里我们先选择不带Rerank模型的向量检索。点击“保存并处理”,等待文档处理结束
等待embedding处理完成,点击“前往文档”,查看向量化后的文档

Step4 文档维护(optional)
文档处理完成以后,我们通常要对文档进行维护,包括查看文本分段,检查分段质量,添加文本分段,编辑文本分段,以及元数据管理(元数据将被用于知识库的分段召回过程中,作为结构化字段参与召回过滤或者显示引用来源)。 这部分内容实验中作为可选内容,请自行参考文档链接进行操作体验:
知识库构建完成以后,我们可以接下来创建一个聊天助手应用,然后让聊天助手基于知识库的内容进行回答。